小白学安全
Python
网络爬虫
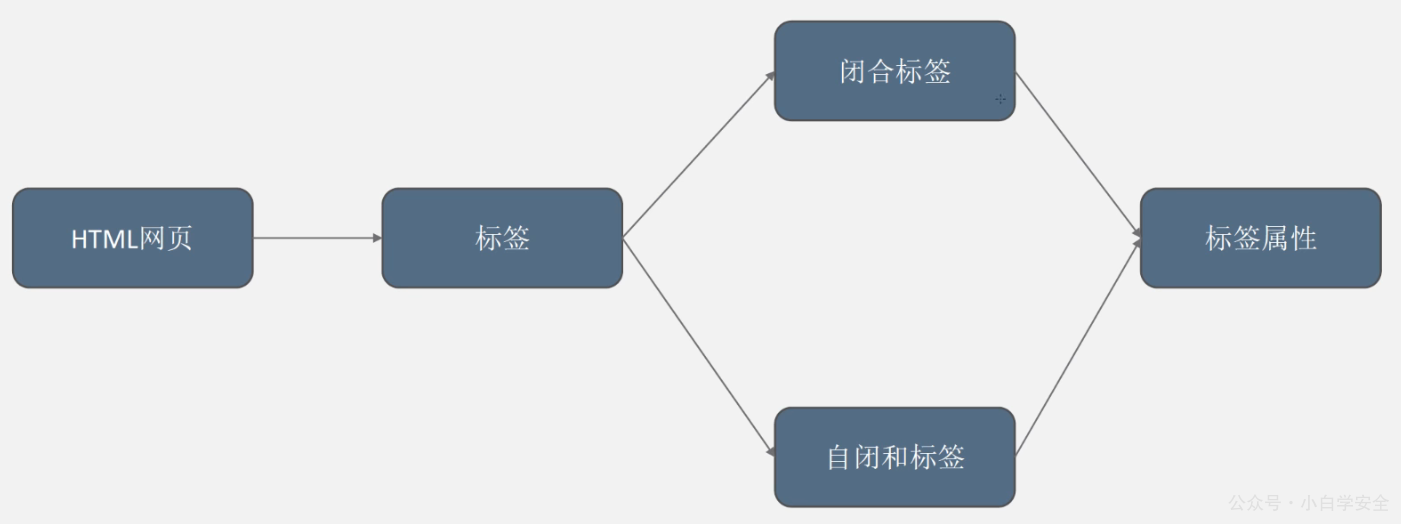
概述概述网络爬虫是一种按照一定规则,自动地抓取万维网信息的程序或者脚本网页中有很多信息和数据,要想从网页中抓取信息和数据,并保存到本地,这就是网络爬虫网页一般是由HTML语言编写,要想从网页中抓取内容,其实就是在HTML中,找到相应的内容进行提取网页大部分的网页由三部分组成HTML -- 超文本标记语言整个网页的结构,类似于人的骨架,定义了你的眼睛、鼻子为位置在哪里CSS -- 层叠样式表CSS表示样式,定义了外观JavaScript -- 脚本语言JavaScript表示功能,网页中的交互内容,交互特效都包含在其中HTML网页结构网络请求当用户浏览器向目标服务器发送请求的过程,称之为网...